
Architecting a scalable Drupal build system with AWS ECS
PreviousNext and our Continuous Integration (build system) have been on a journey for the past 3 years. We are now onto our 3rd generation and would like to share with you some of the concepts and technologies behind it.
Introduction
If you would like to read about version 2 before jumping into this please read my previous blog:
https://www.previousnext.com.au/blog/drupal-continuous-integration-docker
So let's set the scene, our build system has been a huge success for us and is a key component of our workflow, but we have started to hit growing pains, these include:
- Sys Ops staff need to update the "Services" attached to a build in the backend so developers can try out new technologies (Apache Solr or Elasticsearch) .
- An updated frontend workflow which requires Sys Ops intervention if required on old projects.
- Our Jenkins was starting to get very slow due to:
- How many builds we have setup (lots of configuration)
- We kept a large amount of data from previous builds (all the builds)
- The amount of plugins installed eg. IRC
- Jenkins slaves becoming unavailable due to the amount of traffic (builds) we were sending
We also want to move to a CI with the following goals:
- Small components / projects.
- Less reliance on Jenkins for functionality.
- Better stability.
- Greater scalability.
So let's talk about the new architecture and how we solve these problems.
The workflow
As I mentioned above, if a change had to be made in a projects' build process Sys Ops would have to make the change in the backend, this was done via a YAML file which Puppet consumed and used to update the Jenkins host configuration.
Here is an example:
builds:
# Triggered at the time of Pull Request.
foo_pr:
human_name: 'FOO: Pull request'
description: 'This build is triggered by Github pull requests.'
project: 'foo'
github_project: 'previousnext/foo'
pull_request: true
application: 'previousnext/lamp'
services:
- { name: 'elasticsearch', service: 'elasticsearch' }
steps:
- { command: 'phing prepare', user: 'deployer' }
- { command: 'phing drush:init', user: 'deployer' }
- { command: 'phing ci:test:pr', user: 'deployer' }
concurrent: true
checkstyle: 'build/logs/checkstyle.xml'
junit: 'build/logs/*/*.xml'
artifacts: 'build/logs/*/*.html'
Quite alot of YAML for one build right? However, the bigger concern is that the infrastructure (pull_request field) and the projects workflow (steps field) are all in the same file. What we really want is:
- A minimal amount of Puppet to setup some Jenkins jobs.
- The workflow / steps committed to be stored in the project.
We have now settled on a .pnxci.yaml file which lives in the root directory of each project, enabling PreviousNext staff to make changes as required.
application: previousnext/lamp
services:
elasticsearch: elasticsearch
prepare: &prepare
- bin/phing prepare
- bin/phing drush:init
test: &test
- bin/phing ci:test
test_pr:
setup: *prepare
steps: *test
test_head:
setup: *prepare
steps: *test
deploy_setup: &deploy_setup
- bundle install --path vendor/bundle
deploy_qa:
setup: *deploy_setup
steps:
- bundle exec cap dev deploy
deploy_staging:
setup: *deploy_setup
steps:
- bundle exec cap staging deploy
deploy_prod:
setup: *deploy_setup
steps:
- bundle exec cap prod deploy
There are some added bonuses from this file as well. This file holds the answers to the standard project question everyone asks when they join a project:
- What technologies does my project interact with?
- How do I test my project?
- How do I deploy my project?
With that in mind, it's great that we have moved this information into the project, but how does this get used for a build.
The build tool
So I know what you are thinking at this point. Travis CI uses a build file in the root of the project as well, why not use it instead? The main reason is we want to keep our builds around after they have finished and expose them via a URL so changes can be tested before going into mainline.
Back to the story...
In alignment with our "Small components" goal we decided to decouple our build process from our Jenkins which now means:
- We only rely on Jenkins for receiving Github webhooks and firing off the correct build.
- Artefact storage eg. Behat or JUnit results.
We also had the goal to support multiple backends:
- Docker
- AWS EC2 instances
- AWS Elastic Container Serivce
What we ended up with was a tool written in Golang which ran through the following stages:
- Read the YAML file for instance configuration.
- Spin up an instance (Container or VM) and link the services.
- Push the code to the instance.
- Run the required steps.
- Pull the code back for artefacts.
We aim to keep this infrastructure as simple as possible so we can maximize on the workflows which occur inside the instances.
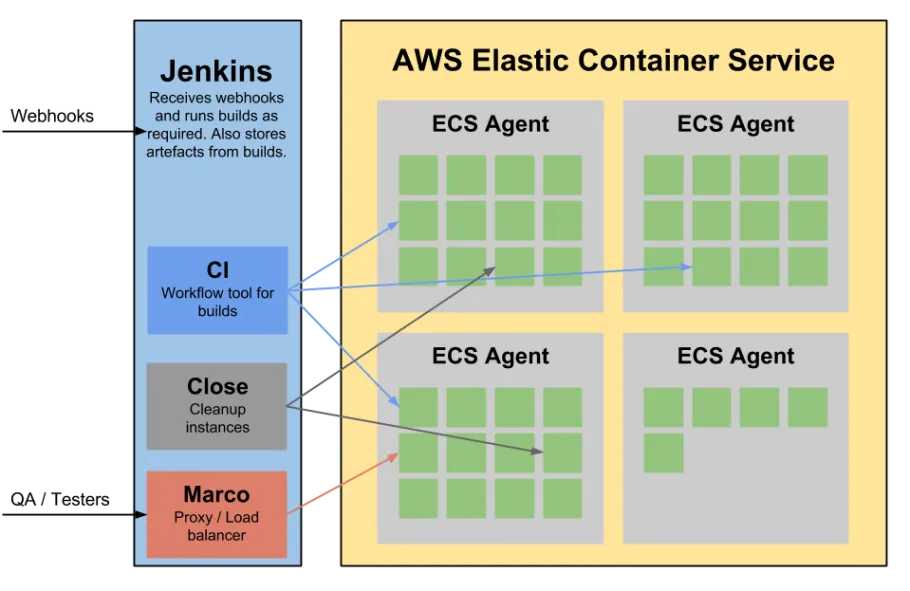
Elastic Container Service
After much consideration we chose to run AWS Elastic Container Service as our build backend of choice.
ECS is a simple yet very powerful service and can be broken down into 4 areas.
- Instance - An EC2 instance running the Agent and Docker daemon.
- Agent - This is installed on a EC2 host running the Docker daemon. It's job is to be the middle man between the ECS API and the Docker daemon thus allowing ECS to tell Docker which containers to run on specific hosts.
- Task - A single unit which runs a specific set of containers eg. LAMP stack container and Elasticsearch.
- Service - Declares a long running Task which also ensuring the task is always running. There is also a workflow component for deployments.
The reasons we chose AWS ECS:
- AWS ship with a Golang API which we leverage to talk to the ECS API and coordinate instances for builds.
- We can autoscale AWS EC2 instances as more compute is required.
Other components
We also wrote some other components along the way.
Marco

We originally created Nginx configuration files per build but realized that it is hard to keep track of them and clean up once a build is ready to be deleted.
To clean this up we now use a Golang Load Balancer called Marco. It's job is to take traffic, query an API and proxy through to the correct build environment.
Here is an example of the type of URL this component will service:
http://foo_pr24.example.com
Close
https://github.com/nickschuch/close
A simple project to clean up environments once a Github Pull Request is closed.
Status
https://github.com/nickschuch/status
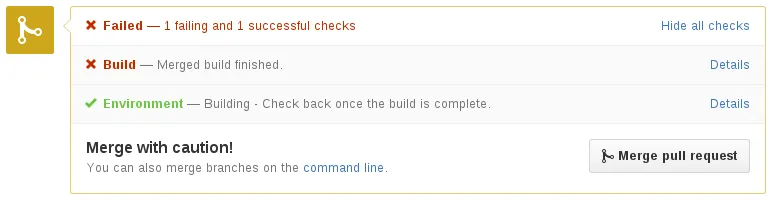
Used for sending status messages to Github. Here is an example of status messages in action.
The final design
Our new architecture can be summed up in the following diagram.
Conclusion
I believe we have now successfully fulfilled the goals that we set out to do in the intro as well as split out our build system into manageable pieces which are easy to iterate against.
Have questions or want to share your own ideas on CI? Post them in the comments!
Tagged
Systems